PDAugment
A data augmentation method for End-to-End Automtic Lyric Transcription Systems
Authors of the paper: Zhang, Chen and Yu, Jiaxing and Chang, LuChin and Tan, Xu and Chen, Jiawei and Qin, Tao and Zhang, Kejun
Introduction
Automatic lyrics transcription (ALT) can be regarded as automatic speech recognition (ASR) on singing voice, and has not been well developed mainly due to the dearth of paired singing voice and lyrics datasets for model training. In this work, we propose PDAugment, a data augmentation method that adjusts pitch and duration of speech at syllable level under the guidance of music scores to help ALT training. Specifically, we adjust the pitch and duration of each syllable in natural speech to those of the corresponding note extracted from music scores, so as to narrow the gap between natural speech and singing voice.
We conduct experiments in two singing voice datasets: DSing30 dataset and Dali corpus. The adjusted LibriSpeech corpus is combined with the singing voice corpus for ALT training. The ALT system with PDAugment outperforms previous SOTA system and Random Aug by 5.9% and 7.8% WERs respectively in DSing30 dataset and 24.9% and 18.1% WERs respectively in Dali corpus. Compared to adding ASR data directly into the training data, our PDAugment has 10.7% and 21.7% WERs reduction in two datasets.
Method
Pipeline Overview
In this work, we follow the practice of current automatic speech recognition systems and choose Conformer encoder and Transformer decoder as our basic model architecture. Moreover, we add a PDAugment module in front of the encoder to apply syllable-level adjustments to pitch and duration of the input natural speech based on the information of aligned notes.
The loss function of the ALT model consists of decoder loss \(\mathcal{L}_{dec}\), and ctc loss (on top of encoder) \(\mathcal{L}_{ctc}\): \(\mathcal{L} = (1-\lambda) \mathcal{L}_{dec} + \lambda \mathcal{L}_{ctc}\), where \(\lambda\) is a hyperparameter to trade-off the two loss terms. Considering that lyrics may contain more musical-specific expressions which are rarely seen in natural speech, the probability distributions of lyrics and standard text are quite different. We train the language model with in-domain lyrics data and then fuse it with ALT model in the beam search of decoding stage.

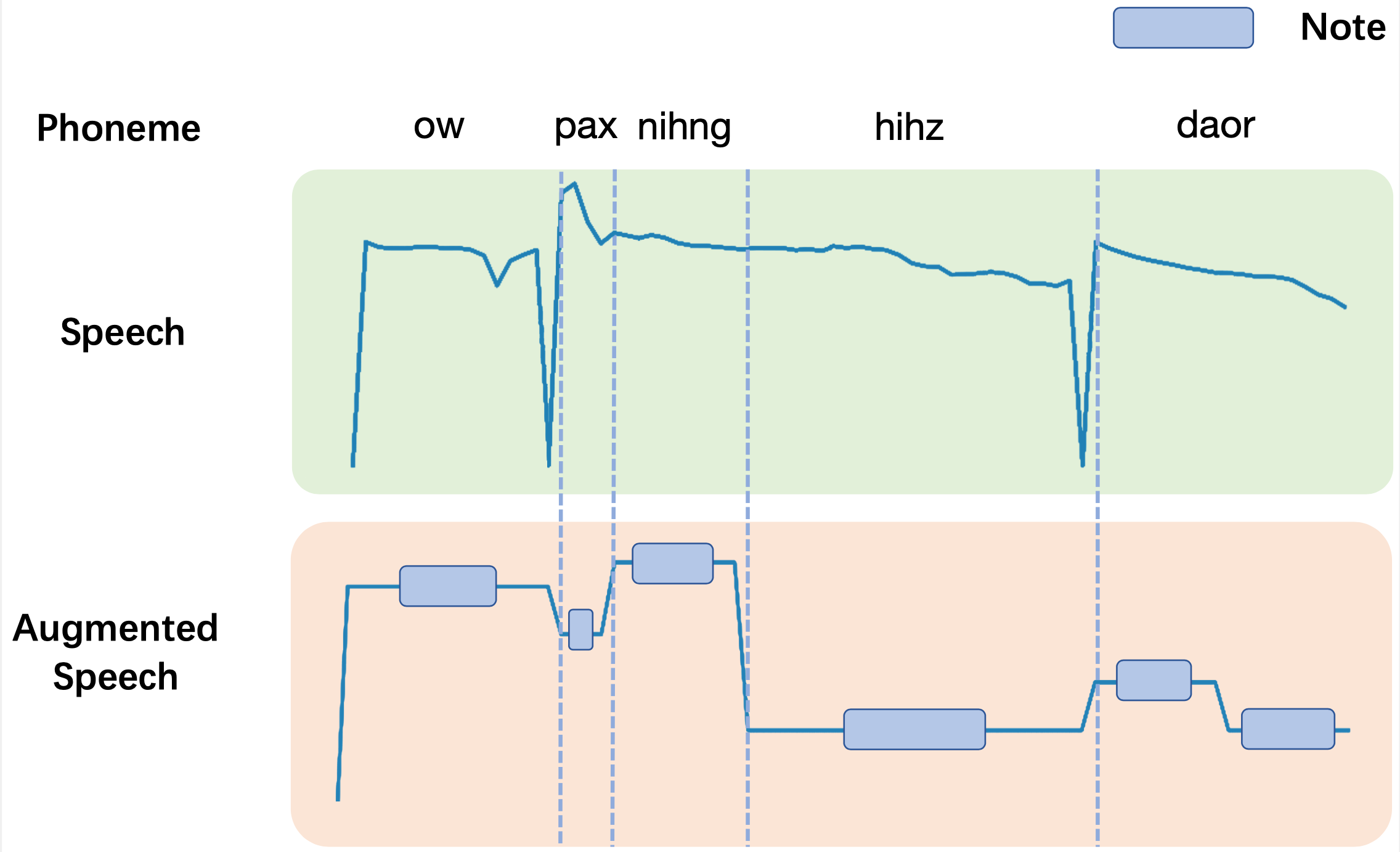
To make speech data fit the patterns of singing voice more naturally to achieve the effect of “singing out” the speech, we adjust the pitch and duration of speech at syllable level according to those of corresponding notes in music scores instead of applying random adjustments. The proposed PDAugment module consists of three key components: 1) speech-note aligner, which generates the syllable-level alignment to decide what the corresponding note of a certain syllable is for subsequent adjusters; 2) pitch adjuster, which adjusts the pitch of each syllable in speech according to the aligned notes from the speech-note aligner; and 3) duration adjuster, which adjusts the duration of each syllable in speech to be in line with the duration of corresponding notes. The three components are introduced in following sections.
Speech-Note Aligner
PDAgument adjusts the pitch and duration of natural speech at syllable level under the guidance of note information obtained from the music scores. In order to apply the syllable-level adjustments, we propose speech-note aligner, which aims to align the speech and note (in melody) at syllable level.
The speech-note aligner aligns the speech with note (in melody) by following steps:
- Convert texts to phonemes and align texts with speech audio at phoneme level. Next, group several phonemes into a syllable according to linguistic rules and get the syllable-level alignment of texts and speech.
- Set one syllable corresponds to one note by default, and only when the time length ratio of the syllable in speech and the note in melody exceeds the predefined thresholds, we generate one-to-many or many-to-one mappings to prevent audio distortion after adjustments.
- Aggregate syllable-level alignment and syllable-to-note mappings to generate the syllable-level alignment of speech and note (in melody) as the input of the pitch and duration adjusters.
Pitch Adjuster
Pitch adjuster adjusts the pitch of input speech at syllable level according to the aligned notes. Specifically, we use WORLD, a vocoder-based speech synthesis system, to implement the adjuster. Some details are as follows:
- To avoid audio distortion when the pitch gap between speech and melody is too large, we calculate the average pitch of speech and corresponding melody respectively. When the gap exceeds the predefined threshold, we shift the pitch of the entire note sequence to make the gap under the threshold.
- To maintain smooth transitions in synthesized speech and prevent speech from being interrupted, we perform pitch interpolation for the frames between two syllables.
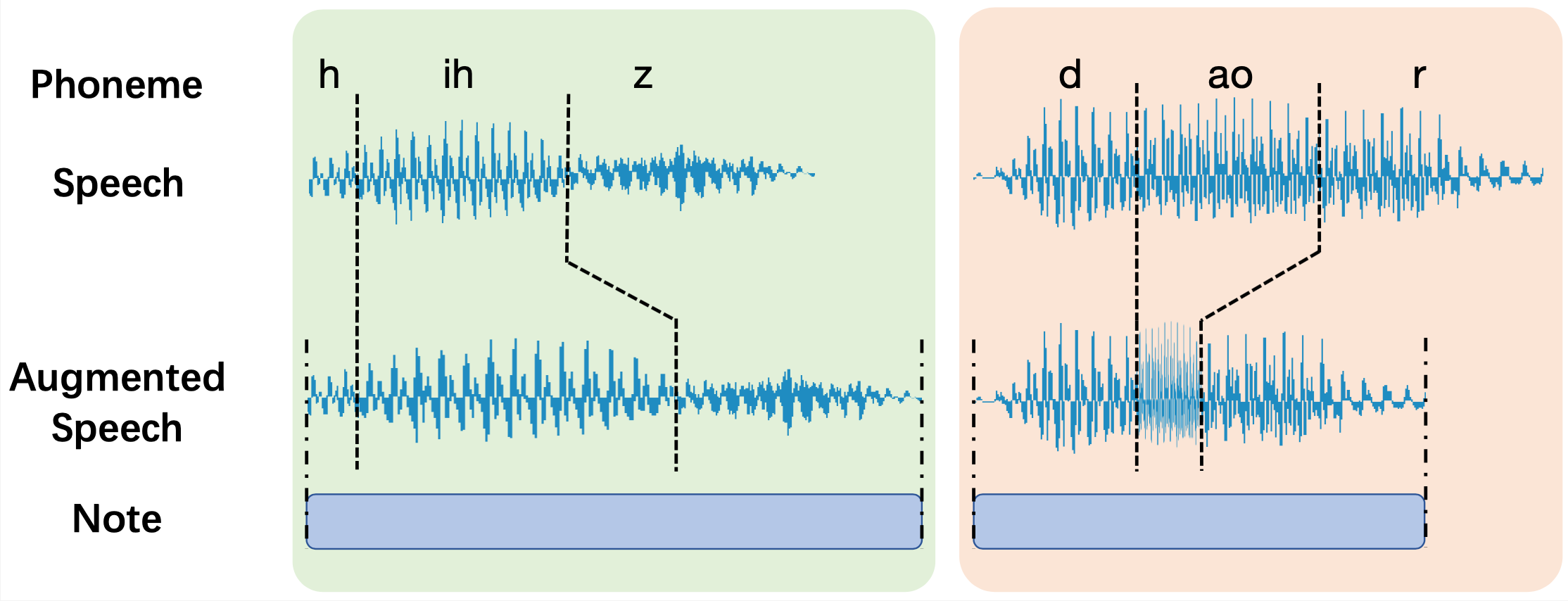
Duration Adjuster
Duration adjuster changes the duration of input speech to align with the duration of corresponding notes. As shown in Figure 3, instead of scaling the whole syllable, we only scale the length of vowels and keep the length of consonants unchanged.
Experiments and Results
We compare our results with several settings as baselines: 1) Naive ALT, the ALT model trained with only singing voice dataset; 2) ASR Augmented, the ALT model trained with the combination of singing voice dataset and ASR data directly; 3) Random Aug (Kruspe and Fraunhofer 2015), the ALT model trained with the combination of singing voice dataset and randomly adjusted ASR data. The pitch is adjusted ranging from -6 to 6 semitones randomly and the duration ratio of speech before and after adjustment is randomly selected from 0.5 to 1.2. All of 1), 2), and 3) are using the same model architecture as PDAugment. Besides the above three baselines, we compare our PDAugment with the previous systems which reported the best results in two datasets respectively. For DSing30 dataset, we compare our PDAugment with Demirel, Ahlback, and Dixon (2020) using RNNLM and the results are shown in Table 1. For Dali corpus, we compare the results with Basak et al. (2021) and report the results in Table 2.


For more experiment details and ablation studies, please refer to the paper and the code repo.
Acknowledgments
This work was done while I was a research assistant at NextLab, Zhejiang University in 2021, and it is part of the Microsoft Muzic open source library.