ReLyMe
A method that incorporates music theory into data-driven music generation models
Authors of the paper: Zhang, Chen and Chang, Luchin and Wu, Songruoyao and Tan, Xu and Qin, Tao and Liu, Tie-Yan and Zhang, Kejun
Introduction
Lyric-to-melody (L2M) generation, which generates melody according to given lyrics, is one of the most important automatic music composition tasks. With the rapid development of deep learning, previous works address this task with end-to-end neural network models. However, deep learning models cannot well capture the strict but subtle relationships between lyrics and melodies, which compromises the harmony between lyrics and generated melodies. In this paper, we propose ReLyMe, a method that incorporates Relationships between Lyrics and Melodies from music theory to ensure the harmony between lyrics and melodies.
In summary, the main contributions of this work are as follows:
- We formulate the relationships between lyrics and melodies from three aspects (tone, rhythm, and structure) based on the music theory summarized by musicians.
- We propose ReLyMe, a method that exploits lyric-melody relationships during the decoding process of neural lyricto-melody generation systems to ensure harmony between generated melodies and corresponding lyrics.
- We conduct experiments on both English and Chinese song datasets and evaluate the generated melodies with objective and subjective evaluation. The results demonstrate the effectiveness of ReLyMe in guaranteeing the harmony between lyrics and melodies and show the significance of incorporating lyric-melody relationships into lyric-to-melody generation.
Method
There are two main parts of this work, which are quantitatizing the relationships between lyrics and melodies from music theory and proposing ReLyMe, which incorporates them into neural lyric-to-melody generation systems. ReLyMe takes effect upon current neural lyric-to-melody generation systems by incorporating relationships between lyrics and melodies.
Considering that the generation process of most current neural network lyric-to-melody generation systems is auto-regressive, ReLyMe involves lyric-melody relationships into neural network models at each decoding step. Specifically, during inference, ReLyMe adjusts the probabilities of each decoding step to influence the current generated token, and further to affect the subsequent tokens.
Denote the training lyric-melody pair as \(\{(\bf{x}, \bf{y}) \in (\bf{\mathcal{X}}, \bf{\mathcal{Y}})\}\). The original score function of beam search in generation system at \(i^{th}\) decoding step is:
\begin{equation} s_i = logP(y_i|y_{0:i-1}, x). \end{equation}
At each decoding step, the constrained decoding mechanism adds the reward \(R_{cons}\) directly to current score. \(R_{cons}(y_{0:i}, x)\) denotes the total reward at \(i^{th}\) decoding step under the musical constraints, which consists of three parts:
- the tone reward \(R_t(y_{0:i}, x)\)
- the rhythm reward \(R_r(y_{0:i}, x)\)
- the structure reward \(R_s(y_{0:i}, x)\)
Thus, the score function in constrained decoding mechanism can be described as:
\begin{equation} s_i’ = logP(y_i|y_{0:i-1}, x) + R_{cons}(y_{0:i}, x). \end{equation}
Then \(s_i'\) is used in beam search as the new score function.
We define the above three rewards based on the relationships between lyrics and melodies. The lyric-melody relationships mean the combining relationships between the rules of lyrics and the rules of the melodies within the scope of unified content, which control the interplay between the lyrics and melodies.

Below, the three aspects of relationships between lyrics and melodies are discussed. For more implication details, please refer to the paper and the code repo.
Tone
When the lyrics are sung with given melodies, the pitches of the lyrics are determined by the melodies instead of the intrinsic tone or stress. Aligning the pitch of the melody with the original pitch of the lyrics is essential for reducing semantic misunderstandings when performing songs. In order to align the melodies with the lyrics at the tonal level, we consider the following three granularities and define the corresponding rewards respectively.
Pitch Shape of a Single Tone.
For each syllable in lyrics, when it corresponds to more than one notes in the melody, the predefined shape of the tone should coincide with the pitch flow of the corresponding note group. Take Mandarin as an example, which contains four main tones (high level tone, rising tone, falling-rising tone, falling tone, denoted as tone1, tone2, tone3, and tone4) and a light tone (unstressed syllable pronounced without its original pitch in Chinese pronunciation, denoted tone5).

Pitch Transition between Adjacent Tones.
For a pair of adjacent syllables within the same sentence, the pitch flow of the corresponding adjacent notes needs to be in line with the pitch transition between tones, otherwise may lead to semantic misunderstanding like the figure below. According to the practice in natural speech, we measure the degree of harmony (excellent, good, fair, poor) for the pitch difference between neighboring notes given each adjacent tone pair.

Pitch Contour of a Whole Sentence.
Lyrics, as a form of text, have their inherent intonation for each sentence to express different emotions and meanings. The pitch contour of a whole sentence depends on the corresponding melody when performing a song, so the pitch direction of the melody needs to be matched to the inherent intonation of the sentence to ensure that the correct meaning is conveyed. For example, an interrogative tends to align with a rising melody (see the orange box of Figure 1).
Rhythm
We consider the rhythmic relationship in two dimensions: 1) intensity at a certain moment, reflected in strong and weak positions; 2) temporal alignment, reflected in pause positions.
Strong/Weak Positions.
Both melodies and lyrics have the “strong” and “weak” elements, and the movement marked by the regulated succession of these elements is described as rhythm. A songwriter tends to align downbeats or accents with stressed syllables or important words. Aligning the rhythm of melody and lyrics helps convey meaning, express empathy and render emotion. The strong and weak positions in melody lines could be determined by multiple factors: pitch, duration, syncopation, meter, and so on. During automatic melody generation, for simplicity, the strong and weak beats can be derived from the predefined time signature. In lyrics, on the other hand, the strong and weak positions are mainly influenced by oral speaking habits, specific semantics, intent of speakers, and expressed emotions. For example, in spoken language, the auxiliary words tend to be pronounced lightly, while the keywords in the lyrics are often regarded as accents, which are pronounced louder to attract the attention of listeners and emphasize the elements. The strong and weak positions of melodies are aligned with those of lyrics to ensure harmony of performance and correct meaning.

Pause Positions.
Pauses in speech divide the entire sentence into several parts with separate meanings (called prosodic phrases) to help the listener understand. Sentences with the same content but different pause positions can have completely different meanings, and the division of prosodic phrases that defies common sense can lead to confusion for listeners. In melody, the pauses are caused by either REST notes or long notes and split the melody into musical phrases, which make complete musical sense when heard on their own. When the lyrics are sung with given melodies, the pause positions are no longer influenced by the spoken idiom but are controlled by the pauses in the melody. A phenomenon called “broken phrases” occurs if syllables of the same prosodic phrase are assigned to different musical phrases. This phenomenon impairs the harmony between the melody and the lyrics and makes the lyrics hard to understand for listeners.

Structure
At the full song level, the structure of lyrics and melody are constrained and influenced by each other. In music, form refers to the structure of a musical composition or performance, including repetition, transition and development. To better convey emotion and show artistry, lyrics and melodies which belong to the same musical form would share the same characteristics like rhyme (in lyrics) or motives (in melodies). Specifically, in lyric-to-melody generation, the melody segments that correspond to the lyrics of the same structure tend to have similar pitch flows.

Experiments and Results
In this work, we apply ReLyMe to SongMass and TeleMelody, two state-of-the-art systems in end-to-end and multi-stage L2M generation systems respectively. For the main experiments, we compare the original version of these two systems with the systems equipped with ReLyMe in Chinese and English. The results are evaluated with the introduced subjective and objective evaluation metrics which are give below.
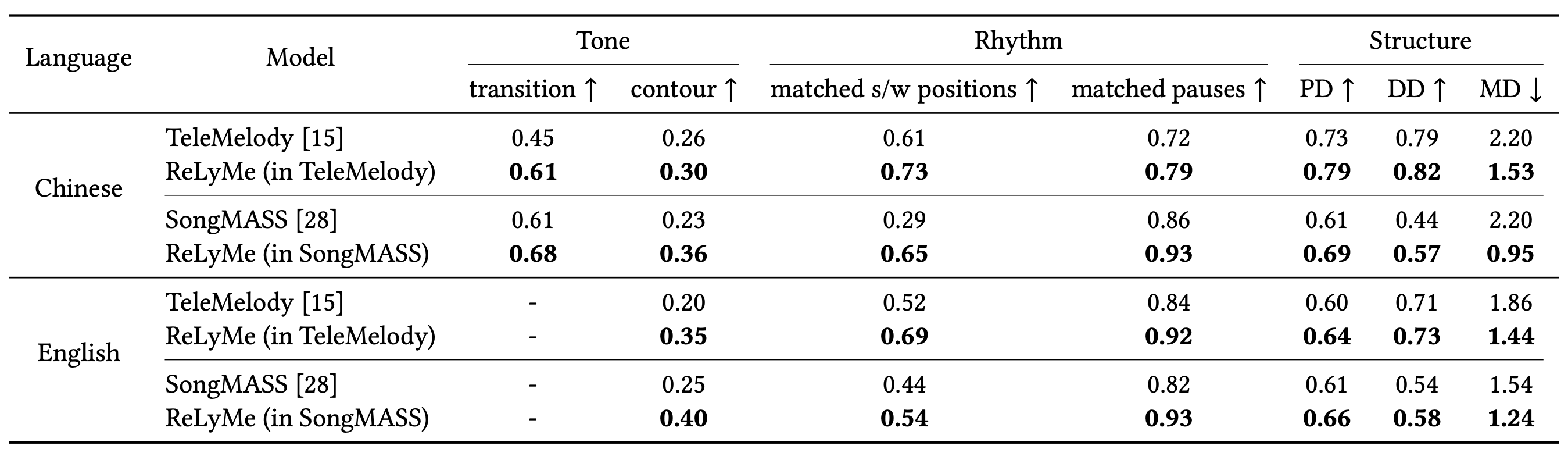
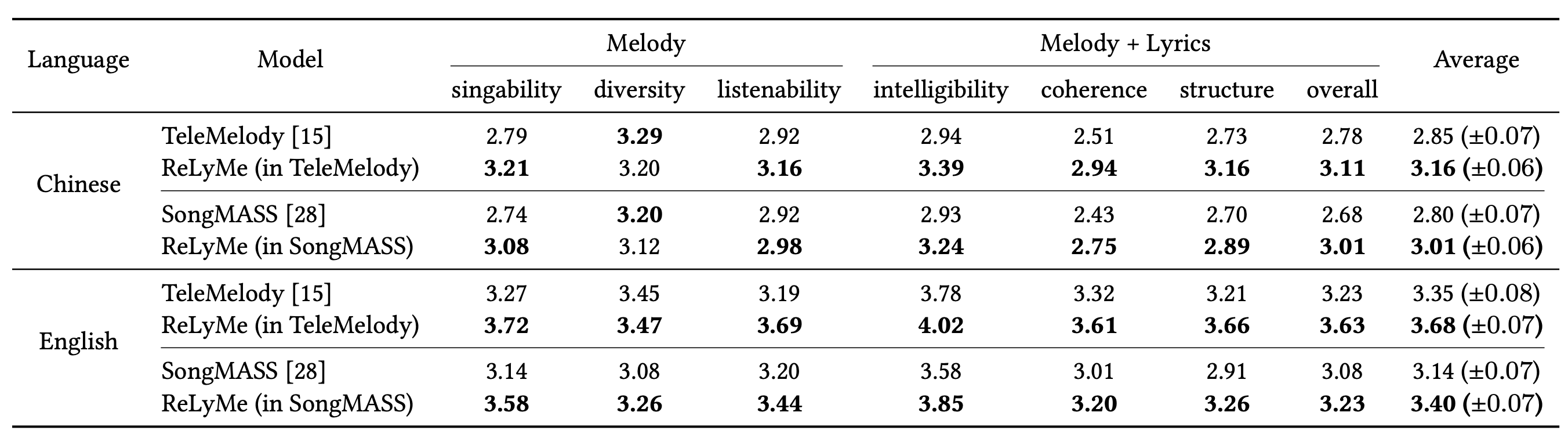
We also perform method analysis discussing:
- Relationships of different aspects (tone, rhythm, structure).
- How strong should the constraints given by the relationships be.
- Different stages of incorporating the relationships (during training, while decoding, after decoding).
Please refer to the paper for more details.
Demo
Acknowledgments
This work was done while I was a research assistant at NextLab, Zhejiang University in 2022, and it is part of the Microsoft Muzic open source library.